こんにちは、サーバーサイドエンジニアの菅原です。
今回はElasticStack6について学んでみたのでその知見を共有したいと思い記事にしました。
はじめに
検索エンジンElasticsearchの検証をしている中でELKと呼ばれるElasticStackの製品について学んでみましたのでそのELKの実行までの流れを記載していきます。
環境
- Mac OS
- Elasticsearch 6.2.4
- Kibana 6.2.3
- Logstash 6.2.3
入門内容
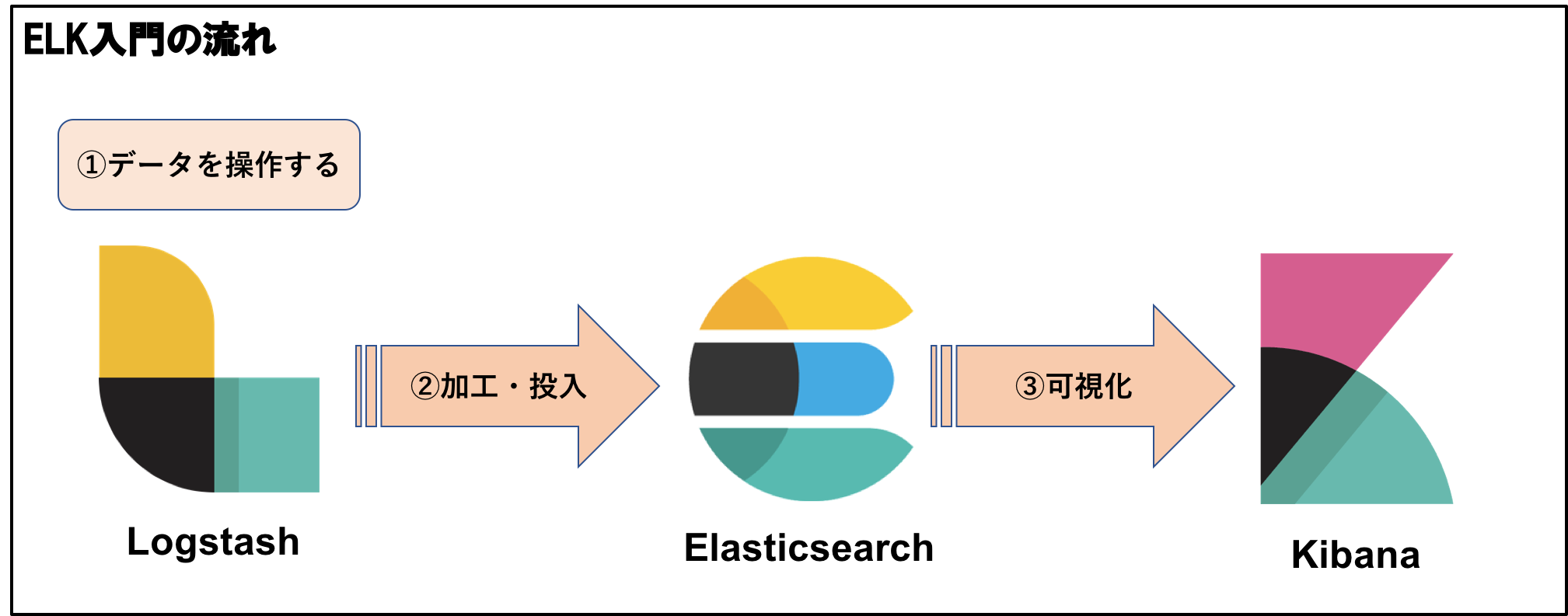
ゴール:ELKの使い方、及び導入からビジュアライズまでの流れを確認する
-
Logstashでデータを扱う
-
LogstashからElasticsearchにデータを加工し投入する
-
KibanaでElasticsearchで投入したデータを可視化する
1 . Logstashでデータを扱う
Logstashをインストールします。
ドキュメント通りにインストールしても問題ないですが今回はhomebrewでインストールしました。
logstashがローカルの /usr/local/bin/logstash にインストールされたことがわかります。
https://www.elastic.co/jp/downloads/logstash
$ brew install logstash $ which logstash /usr/local/bin/logstash
では Logstashを実際に起動させて動作を確認していきましょう
Logstashを扱うためにはLogstashにどんなデータに対して(input)どのように加工し(filter)どう出力(output)するかを設定するためのconfファイルが必要になるのでファイルを作りましょう。
ファイルはどこでも大丈夫なのですがここでは /usr/local/Cellar/logstash/6.2.4/bin 配下に logstash.conf を配置しました。
// どんなデータに対して
input { stdin {} }
// どのように加工するか
filter {}
// どう出力するか
output {
stdout {
codec => rubydebug
}
}
上記を配置しますが今はlogstash.confの雛形をおいただけなので特に設定などは記していません。
実際に起動して確認していきましょう
$ /usr/local/bin/logstash -f logstash.conf
成功すると最終行にこのような出力でコマンドラインが止まることを確認します。
Pipelines running {:count=>1, :pipelines=>["main"]}
こちらの状態で文字列を入力してみます。
Pipelines running {:count=>1, :pipelines=>["main"]}
Hello!
{
"host" => "host",
"@timestamp" => 2018-06-17T11:38:44.370Z,
"message" => "Hello!",
"@version" => "1"
}
Logstash側から上記のレスポンスが返ってくることが確認できます。
Hello! というメッセージが messageのフィールドに存在していることがわかります。
それではlogstash.confでデータを加工してみましょう
データの加工にはfilterを使います。
filterにも様々な加工を施すAPIが用意されております。
https://www.elastic.co/guide/en/logstash/current/filter-plugins.html
この中で grok と呼ばれるapacheなどのログをフィルタリングするときに便利なfilterを使ってみます。
logstash.confのfilter内にgrokフィールドを追加します。
input { stdin {} }
filter {
grok {
match => {
"message" => '%{HTTPDATE:date} %{IP:ip} '
}
}
}
output {
stdout {
codec => rubydebug
}
}
上記の設定で保存したらひとまず上記を実行してみます。
$ /usr/local/bin/logstash -f logstash.conf
立ち上がったことが確認できたら以下を入力します。
18/July/2018:19:38:00 -0700 183.60.215.50
18/July/2018:19:38:00 -0700 183.60.215.50
{
"@timestamp" => 2018-06-17T15:31:18.991Z,
"message" => "18/July/2018:19:38:00 183.60.215.50 ",
"msg" => "Hello!",
"ip" => "183.60.215.50",
"@version" => "1",
"date" => "18/July/2018:19:38:00 -0700",
"host" => "WP3N-219"
}
レスポンスをみるとフィールドが増えていることがわかります。
入力したログをfilterで確認してデータを分割してくれているのです。
HTTPDATEには日付、IPにはipアドレス、DATAにはメッセージデータが入っていることがわかります。
このようにしてElasticsearchにデータを送る際に事前に加工することによってKibanaで可視化しやすくしたり
Elasticsearchのマッピングに対応した値を投入することができます。
マッピングについては後ほど。。
2. LogstashからElasticsearchにデータを加工し投入する
Logstashでデータを加工して操作することができました。次に加工したデータをElasticsearch側に投入していく準備をします。
Logstashにはデータを扱うためのAPIがデフォルトで様々なファイル形式やサービスに対して扱うことができます。
https://www.elastic.co/guide/en/logstash/current/input-plugins.html
今回はCSV形式のファイルでLogstashからElasticsearch側にデータを送る準備をしましょう
商品情報が入った product.csv というcsvを事前に用意します。
中身は id, title, description, manufacturer, priceのセルの列を持ったデータを用意します。
logstash.confを以下のように編集します
// fileAPIを使ってpathのcsvを指定します。
// 起動したタイミングで読み込みたいのでbegining (デフォルトはend)
// どこまで投入できたかどうかを覚えておくログを吐き出すパス(今回は設定しない)
input {
file {
path => "~/Desktop/products.csv"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
// 「,」でくぎられたところでカラムには一列目のセルの名前を入れます
// mutateでカラムの型のタイプを指定したり、加工したり、フィールドに入るデータを制御したりすることができます。
// 今回は必要ないfieldを抜いて対応しています。
filter {
csv {
separator => ","
columns => ["id","title","description","manufacturer","price"]
}
mutate {
remove_field => ["@version","path","host", "tags", "message"]
}
}
// ローカルの9200ポートでelasticsearchを起動しているのでhostsを向けます
// indexにはRDBMSでいうDB名を指定し
// document_typeにはRDBMSでいうテーブル名を指定します
output {
elasticsearch {
hosts => "http://localhost:9200"
index => "wp_products"
document_type => "products"
}
stdout {}
}
上記の設定ができたらデータを投入していきましょう!
先ほどと同じようにlogstash.confの設定を元にlogstashを起動してあげます。
$ /usr/local/bin/logstash -f logstash.conf
するとたくさんのデータが投入されていることがわかります。
記事では一部データが投入されているところを記載しております。
~~中略~~
{
"title" => "kensington contour pro 17 notebook carrying case (62340)",
"manufacturer" => "kensington",
"price" => "89.99",
"id" => "b0000dbmhr",
"@timestamp" => 2018-06-17T10:38:45.141Z,
"description" => "kensington 62340a contour pro 17 notebook carrying case - the contour pro 17 offers premium protection and exceptional comfort in one outstanding case. not only does its snugfit? protection system keep your notebook computer safe its contour panel and weight distribution system helps reduce weight impact by 35% so the case feels lighter. shock-absorbing contour shoulder strap is secure and comfortable convenient compartment for on-the-go access to aircraft tickets et al 1680 denier ballistic nylon protects against abrasions punctures and tears front pockets laid out for easy organization and access padded rear compartment keeps peripherals from poking through contour pro 17 notebook carrying case is backed by the kensington lifetime warranty."
}
{
"title" => "now up-to-date & contact v5.0 (mac)",
"manufacturer" => "now software",
"price" => "0",
"id" => "b000a7q6n8",
"@timestamp" => 2018-06-17T10:38:45.142Z,
"description" => "now up-to-date & contact is the only solution that addresses all of the problems that businesses and power users face. productivity is a lot like the weather. everyone talks about it but nobody does anything about it. staying organized is a continual struggle for most people. now you can manage all your appointments contacts notes and information. it's the solution for your busy modern life. best of all it's fully cross-platform -- it doesn't matter if you use macs or windows it looks and acts the same on both. professional rapid response via online support system automated faq and free email support"
}
~~中略~~
投入が終わり次第Elasticsearchでデータができているかの確認をします。
curl -XGET "http://localhost:9200/wp_products/products/_search?pretty"
すると約1363件のデータが入っていることが確認できます。
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 1363,
"max_score" : 1.0,
"hits" : [
{
"_index" : "wp_products",
"_type" : "products",
"_id" : "cwtMDWQBLzsARdUAhfb1",
"_score" : 1.0,
"_source" : {
"title" : "clickart 950 000 - premier image pack (dvd-rom)",
"price" : "0",
"id" : "b000jz4hqo",
"description" : null,
"manufacturer" : "broderbund"
}
},
確認できたらKibanaでデータを可視化していきましょう
3. KibanaでElasticsearchで投入したデータを可視化する
それではKibanaでデータを可視化していきましょう(5601ポートでKibanaを起動しています)
先ほど追加したindexの「wp_products」をManagementバーからindex_patternsに追加してあげます。
追加ができたらサイドバーのDiscoverから「wp_products」のインデックスが登録されていることがわかります。
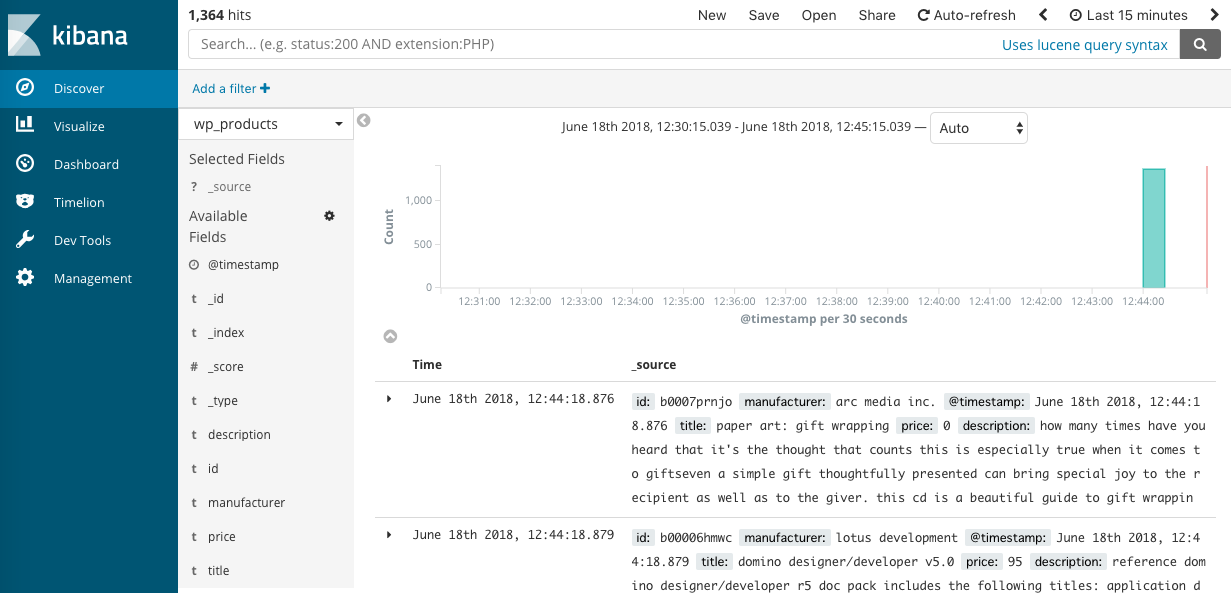
登録が確認できたら早速ビジュアライズしていきましょう
サイドバーのVisualizeを押してビジュアライズしたい図・表を選択します。
今回はPieチャートを選択します。
選択したらPieチャートが表示されていることがわかります。
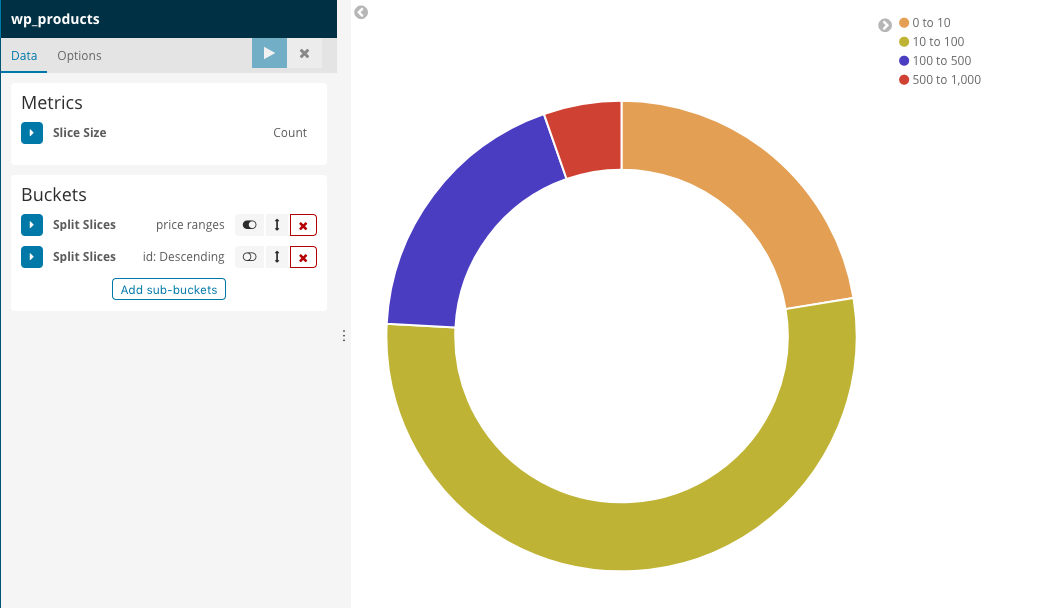
このPieチャートに条件をつけていきます。
- Priceの範囲(range)で分けてみよう
Bucketsのsplit sliceからRangeでグルーピングして対象フィールドを「Price」にし範囲を設定します。
するとこのようにPieに色がつくことがわかります。
- Priceに対してどのような商品があるのかTermsでIDを使って可視化してみます
先ほどのrangeに追加で商品ID(Terms)を追加してorderで件数を指定して実行してみましょう
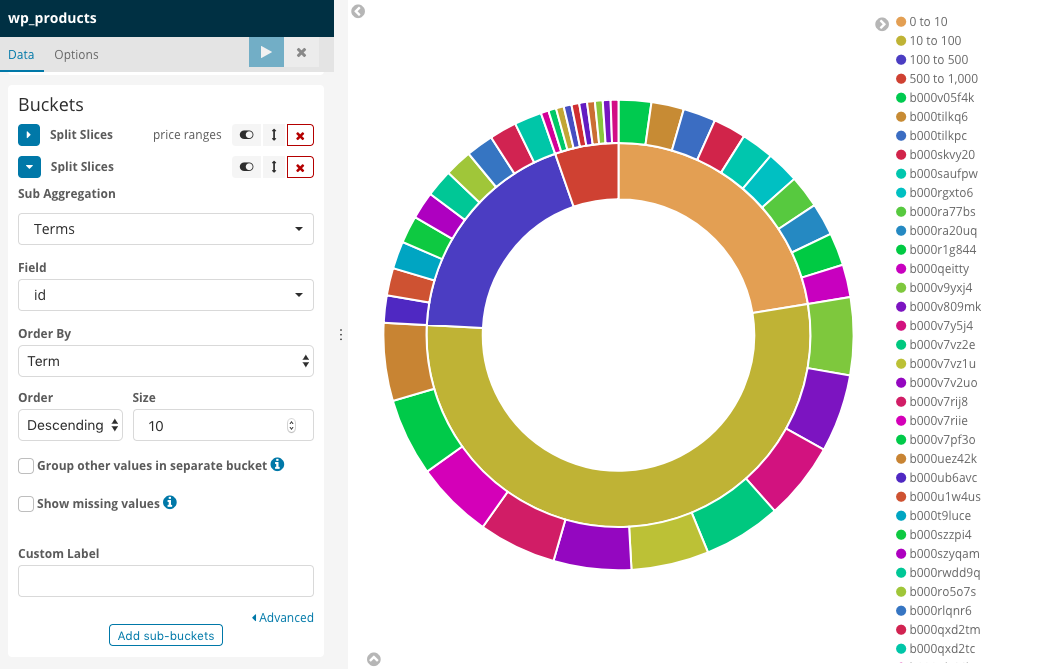
どのような商品が入っているかビジュアライズできたことがわかります。
このように様々な条件で図・表をビジュアライズ化し、ダッシュボードを作成することもできます。
x-packのKibana Canvasを用いるとリアルタイムでダッシュボードが更新されていくためこちらも今後は触ってみたいです。
以上でELKの流れを知ることができました。
補足(マッピングについて)
LogstashからElasticsearch側にデータを投入する際にElasticsearch側では何もせずにデータを投入しました。
しかし、実際の業務に使うにはすごく危険です。
というのも wp_productsのマッピングと呼ばれる(RDBMSでいうテーブル設計)を事前に定義しておかないと期待した挙動をしてくれないことがあるからです。
今回のデータでいうとpriceが当てはまります。
今回priceにはドルの単位の小数点を含んだ数字が入ります。
実際にマッピングを定義しないで投入したマッピングをみてみます。
$ curl -XGET "http://localhost:9200/wp_products/_mapping?pretty"
"wp_products" : {
"mappings" : {
"products" : {
"properties" : {
"@timestamp" : {
"type" : "date"
},
~~ 中略 ~~
"price" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
~~ 中略 ~~
}
}
するとpriceフィールドの型がtextになっていることがわかります。
これでは検索クエリでpriceのrangeを絞った場合に意図しない挙動を招きかねません。
そういう事態にならないためにも事前にテーブル定義のようにマッピングを作る必要があります。
小数点がつくマッピングにはpriceに対してfloatの型を指定してあげる必要があります。
今回はmappingに対して新しく追加された型 scaled_float を指定しています。
これはfloatで入ったデータに対してscaling_factorに記述している100を掛け合わせることで
整数値integerに変更するようにしています。これによってコンピュータがfloatにかかる検索処理時間を短縮し
かつdisk容量も減らせることができるので検索時にもパフォーマンスがよくなるからです。
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"products": {
"properties": {
"id": {
"type": "keyword"
},
"title": {
"type": "text"
},
"description": {
"type": "text"
},
"manufacturer": {
"type": "text",
"fields": {
"raw": {
"type": "keyword"
}
}
},
"price": {
"type": "scaled_float",
"scaling_factor": 100
}
}
}
}
}
まとめ
いかがでしたか?今回はElasticStack6のELKの基本操作の入門をしました。
プログラミング的要素は多くなく、とっかかりやすく理解もしやすい印象でした。
ElasticStack製品は設定がかなり細かくでき仕様が深くバージョンアップの頻度も高いため
どんなデータに対しても対応策がかなりあり良い反面、知っていないと使えないツールなのでドキュメントを通じて今後も学んでアウトプットしていきたいです。
この度は、ご清覧頂きありがとうございました。
Wedding Parkでは一緒に技術のウエディングパークを創っていくエンジニアを募集しています。
興味のある方はぜひ一度気軽にオフィスに遊びにいらして頂ければと思います。
