新卒1年目が本配属で学んだ「エンジニアとして大切だと考えるソフトスキル」
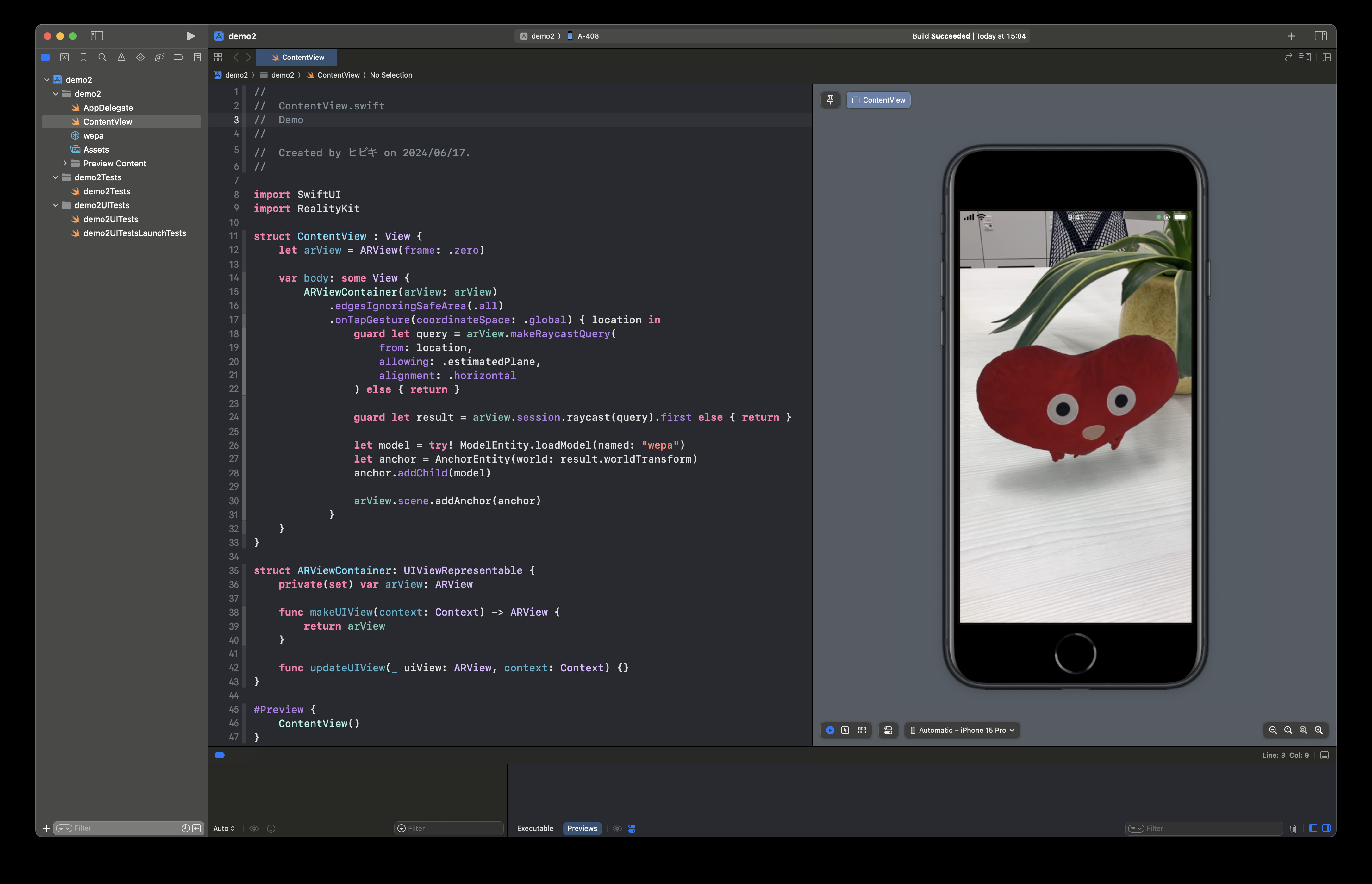
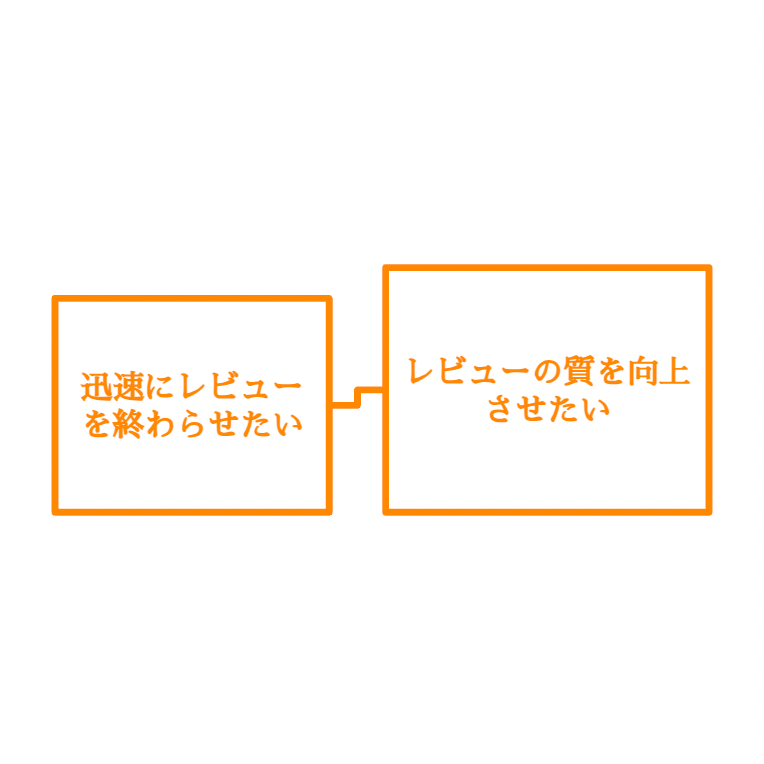
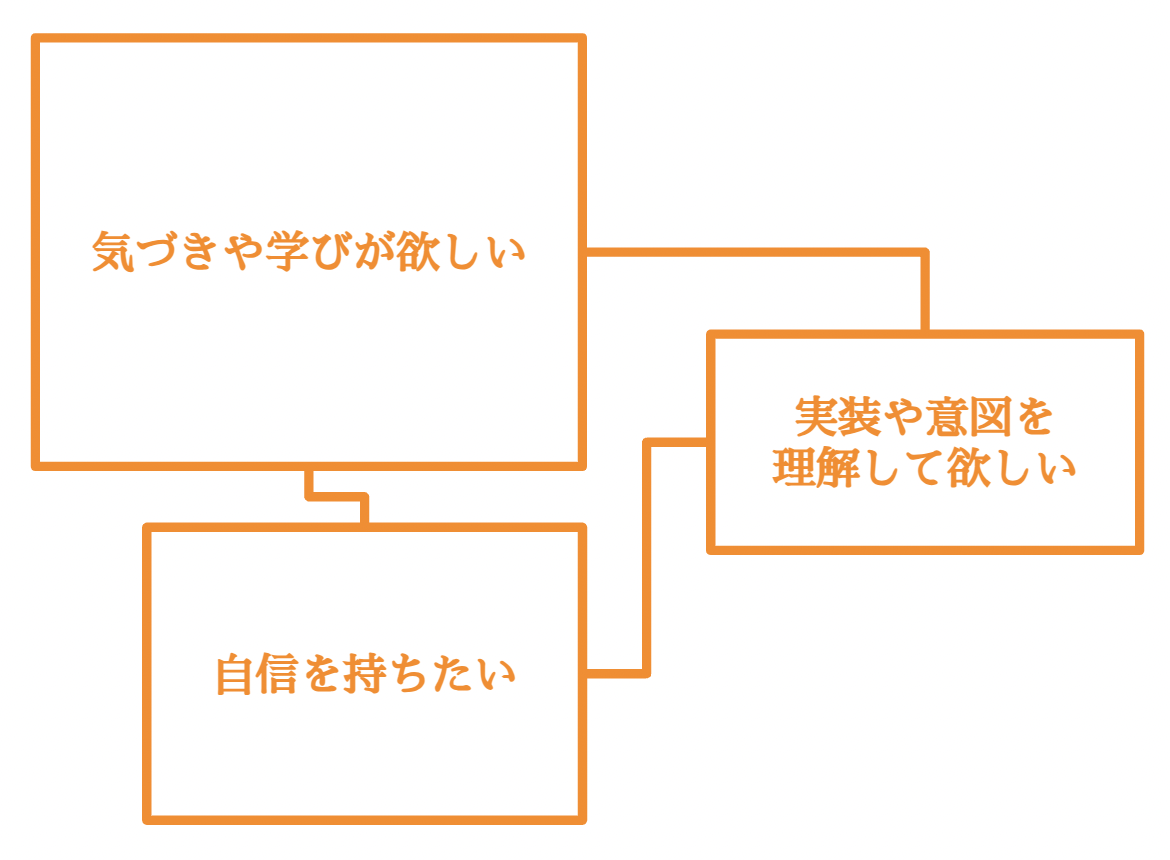
こんにちは!新卒1年目エンジニアのShiromaruです! 入社から半年が経ち、本配属から3か月が経ちました。開発チームの一員として様々な業務に取り組む中で、技術的な「ハードスキル」はもちろん、それ以上に「ソフトスキル」 […]
チーム

PHPカンファレンス2025で登壇、スポンサーブースレポート
こんにちは。TECH戦略室・SREエンジニアのヒエイです。 6月28日に行われたPHPカンファレンス2025で登壇をしてきました! https://phpcon.php.gr.jp/2025/ そしてウエディングパークは […]
SRE/インフラ

PlaywrightとMagicPodをGitHub Actionsに組み込んでみた
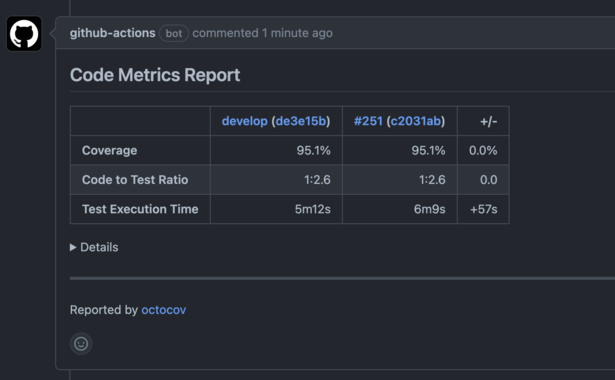
こんにちは! 新卒1年目エンジニアのyu-yaです! (そんな私ももうすぐ2年目になります…はやい…) 先日、PlaywrightとMagicPodをGitHub Actionsに組み込む検証を行 […]
QA/テスト
新卒1年目でメインサービスの仕様を勉強してみた!
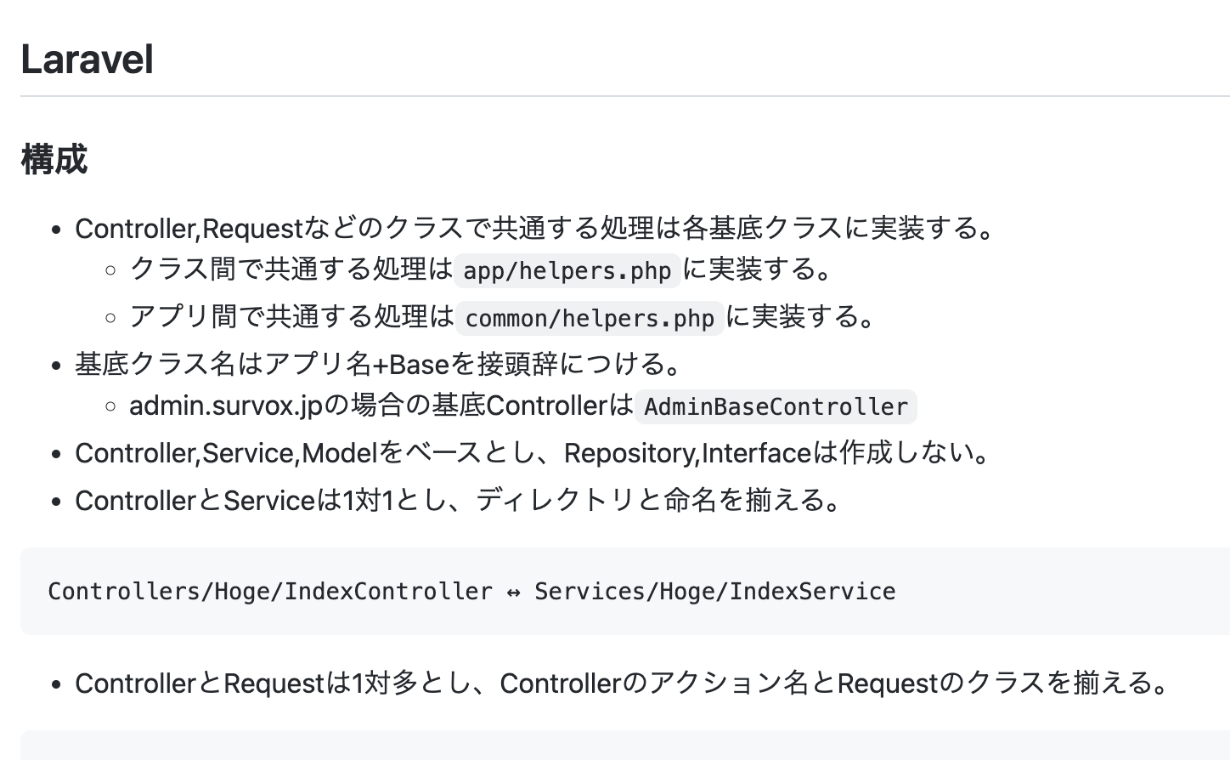
こんにちは! 新卒1年目エンジニアのshimatsuです! 先日、同期のエンジニアメンバーで、弊社のメインサービスの仕様について勉強する場を設けました。 なぜこのような場を設けようと思ったのか、そして具体的にどのようなフ […]
その他
.jpeg)