はじめに
こんにちは、岩橋聡吾です。
今回から複数回に渡って、Python機械学習ライブラリscikit-learnのcheat-sheetを解説してみたいと思います。
筆者が機械学習を勉強し始めた際、ニューラルネットワーク・サポートベクターマシン・ランダムフォレストなど…アルゴリズムばかりが先に情報として溢れていて「機械学習」を俯瞰して体系的に見ることが難しい状況でした。
結局何ができるの?…そんな時に出会ったのが、この「cheat-sheet」でした。
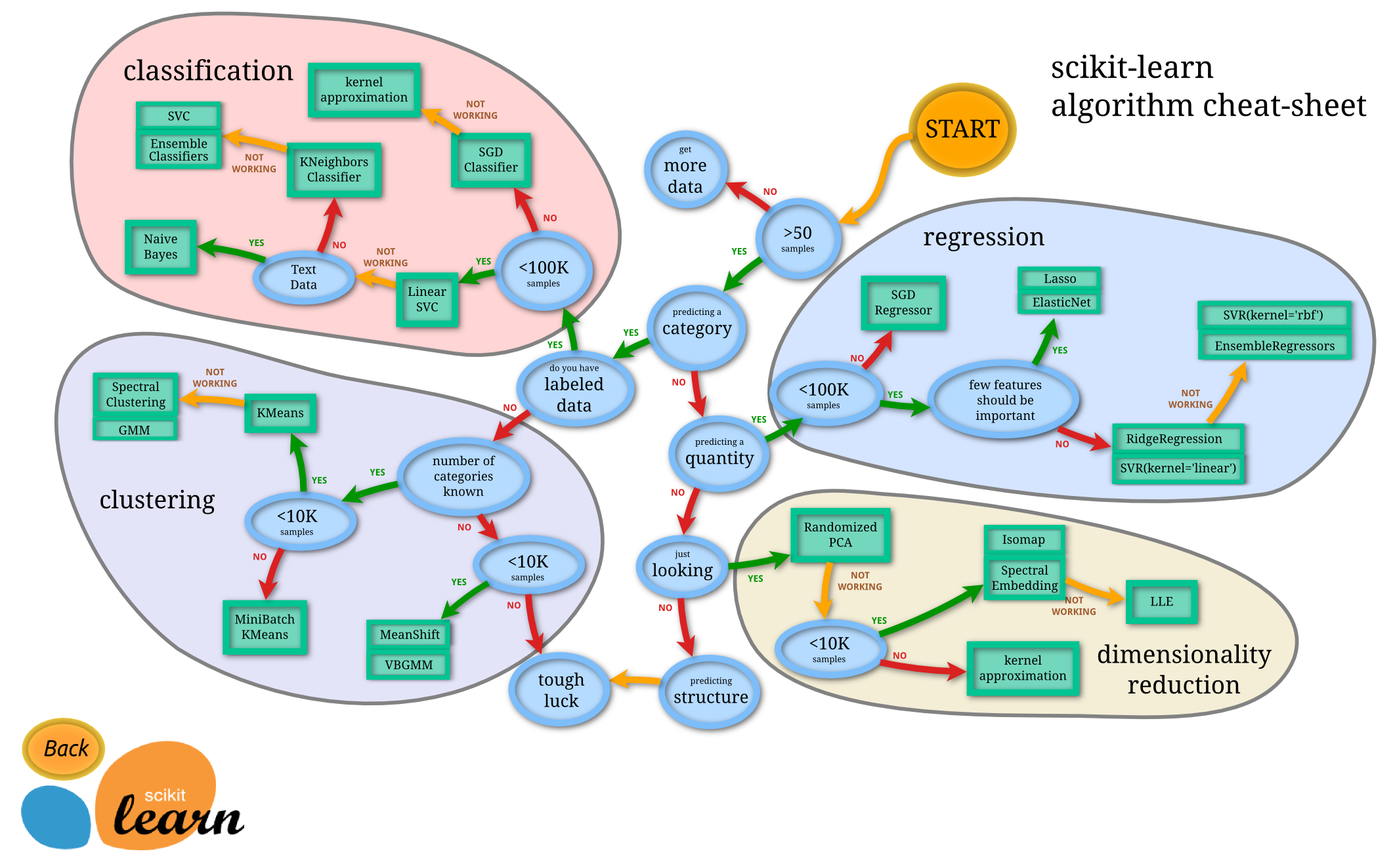
このcheat-sheetから、機械学習は大きく回帰・識別・分類・次元削減=主成分分析の4つの目的の達成の為に使用されること、そしてその目的と状況に応じてアルゴリズムが決定されることがわかります。
この4つの目的を組み合わせることで、あらゆることを可能にするのが「機械学習」となります。
第1回では、cheat-sheetの解説と少し実践もしてみたいと思います。最終的には今回紹介する全てのアルゴリズムを実践したいと思っています…汗。
scikit-learn cheat-sheet の解説
classification(識別:教師あり学習)
◉ざっくり言うと:
『特徴』と『グループ』のデータセットを教師学習とし、グループが分からない『特徴』データを入力した場合に『グループ』を識別。
◉こんなイメージで使われる:
・今日の風の強さから明日の天候(晴れ・曇り・雨)を識別
・身長、体重とシワの数から性別(男・女)を識別
◉アルゴリズムの選び方:
【SGD識別】
・教師学習用のデータセットが100,000以上ないとき【kernel近似識別】
・教師学習用のデータセットが100,000以上ないとき
・SGD識別がうまくいかない(非線形での識別が必要な)とき【LinearSVC識別】
・教師学習用のデータセットが100,000以上あるとき【k近傍法識別】
・教師学習用のデータセットが100,000以上あるとき
・LinearSVC識別がうまくいかない(非線形での識別が必要な)とき
・サンプルデータセットがテキストデータでないとき【SVC識別】【Ensemble識別】
・教師学習用のデータセットが100,000以上あるとき
・k近傍法識別がうまくいかないとき
・サンプルデータセットがテキストデータでないとき【ナイーブベイズ識別(テキストデータ専門)】
・教師学習用のデータセットが100,000以上あるとき
・LinearSVC識別がうまくいかない(非線形での識別が必要な)とき
・サンプルデータセットがテキストデータであるとき
ex)迷惑メールかそうでないかの識別などが可能。
regression(回帰:教師あり学習)
◉ざっくり言うと:
『手掛かり』と『答え』のデータセットを教師学習とし、答えが分からない『手掛かり』データを入力した場合に『答え』を予測(数値から数値を予測)。
◉こんなイメージで使われる:
・今日の風の強さから明日の気温を予測
・身長、体重とシワの数から年齢を予測 – *1
◉アルゴリズムの選び方:
【SGD回帰】
・教師学習用のデータセットが100,000以上ないとき【Lasso回帰】【ElasticNet回帰】
・教師学習用のデータセットが100,000以上あるとき
・全ての特徴量が重要でない(重要な特徴の考察をしたい)とき
ex)*1の場合、シワの数が重要、身長と体重は重要でないというような考察が可能。【Ridge回帰】【LinearSVR回帰】
・教師学習用のデータセットが100,000以上あるとき
・全ての特徴量が重要であるとき【SVR回帰】【Ensemble回帰】
・教師学習用のデータセットが100,000以上あるとき
・全ての特徴量が重要であるとき
・Ridge回帰、LinesarSVR回帰がうまくいかない(非線形での回帰が必要な)とき
clustering(分類:教師なし学習)
◉ざっくり言うと:
漠然とした『特徴』のデータセットをパターン(似ている・近しい特徴)を見つけて分類(塊化)。特に、簡単に分類できなさそうなものについて『グループ』を定義しやすくする為の手段。
◉こんなイメージで使われる:
・公園の砂場の砂(硬度・強度・色 etc)の粒子をいくつかの塊に分類。
・夜空の星(光の強さ・色・距離・温度 etc)をいくつかの塊に分類。
◉アルゴリズムの選び方:
【MeanShift分類】【VBGMM分類】
・分類する塊の数を指定しないとき
・対象のデータセットが100,000以上あるとき【MiniBatchKMeans分類】
・分類する塊の数を指定するとき
・対象のデータセットが100,000以上ないとき【KMeans分類】
・分類する塊の数を指定するとき
・対象のデータセットが100,000以上あるとき【スペクタクル分類】【GMM分類】
・分類する塊の数を指定するとき
・対象のデータセットが100,000以上あるとき
・KMeans分類がうまくいかない(非線形での分類が必要な)とき
dimensionality reduction(次元削減,主成分分析:教師なし学習)
◉ざっくり言うと:
データのばらつきが大きい部分に着目し、逆にばらつきが小さい部分を無視するような視点に変換することで、データ圧縮(次元削減)や主成分分析を実施する手段。3次元を2次元に落とし込み状況を把握しやすくするという点で写真を撮り・写真から判断するという行為に似ている。
◉こんなイメージで使われる:
・画像などの大きいデータの次元を削減。
◉アルゴリズムの選び方:
【ランダマイズPCA】
・先ずこれを試す【kernel近似PCA】
・ランダマイズPCAがうまくいかない(データセットの構造が非線形である)とき
・対象のデータセットが100,000以上ないとき【Isomap PCA】【SpectralEmbedding PCA】
・ランダマイズPCAがうまくいかない(データセットの構造が非線形である)とき
・対象のデータセットが100,000以上あるとき【LLE PCA】
・データセットの構造が非線形である
・対象のデータセットが100,000以上あるとき
・IsomapPCA、SpectralEmbeddingPCAがうまくいかないとき
実践!classification(識別:教師あり学習)をやってみた
それでは、classificationの【SGD識別】アルゴリズムを使った実践していきます。
今回は上記アルゴリズムを使って、アヤメ(花)の「種類」をその「花びらの長さ」と「がくの長さ」から識別してみたいと思います。

Pythonで機械学習環境を構築
①「Anaconda」をPCにインストール
AnacondaはPythonと機械学習でよく使うライブラリを、まとめてインストールしてくれます。
▷Anacondaインストール方法(Windows)
②jupyter notebookの起動
jupyter notebookはpythonの実行環境の一つです。
▷jupyter notebookの使い方(Windows)
実装
先ず使用するライブラリをインポートしていきます。
#使用ライブラリインポート import numpy as np #numpyという行列などを扱うライブラリを利用 import pandas as pd #pandasというデータ分析ライブラリを利用 import matplotlib.pyplot as plt #プロット用のライブラリを利用 from sklearn import linear_model, metrics, preprocessing, cross_validation #機械学習用のライブラリを利用
次にデータセットを読み込みます。
機械学習を勉強していく上でサンプルデータは必要不可欠です。
以下は筆者がよく使うサイトで様々なサンプルデータを提供してくれます。今回もこちらからサンプルデータを借りることにします。
▷UCI
▷UCI_アヤメのデータセット詳細
#データセットの読み込み
df_iris_all=pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/iris/bezdekIris.data', header=None)
念の為データの中身を確認しましょう。
#データの表示 df_iris_all.columns=['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class'] df_iris_all.head()
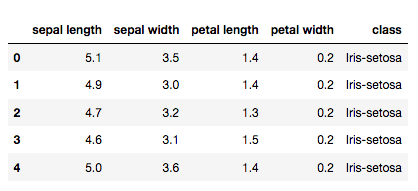
今回はこの中から、
・class=品種
・petal-length=花びらの長さ
・sepal-length=がくの長さ
を使用します。
#「class」と「petal-length」と「sepal-length」を使用 df_iris=df_iris_all[['class', 'petal-length', 'sepal-length']]
次にデータの標準化です。
このままSGDアルゴリズムを用いて識別することも可能ですが、標準化することで精度の高い予測が可能になります。
データセットは、次元によって数値の単位がバラバラであったり、大きさが極端に異なったりする場合がよくあります。そのまま扱ってしまうと、各次元を見比べたときにそれぞれの関係が分かり辛く、また機械学習においては特定の次元の影響が強く (または弱く) 出てしまうこともあります。
そこで使用するデータセットの各次元のスケールを揃えてあげることで、前述のようなリスクを防ぐことができます。これを標準化と言います。
#データの標準化 data=df_iris[['petal-length', 'sepal-length']] sc=preprocessing.StandardScaler() sc.fit(data) std_data=sc.transform(data)
#見やすくする為「class」を数値に置き換える(Iris-setosa:0 Iris-versicolor:1 Iris-virginica:2)
label=df_iris[u'class'].replace('Iris-setosa', 0).replace('Iris-versicolor', 1).replace('Iris-virginica', 2)
次に【SGD識別】アルゴリズムの準備をします。
その際に損失計算に使われる関数を指定します。今回はヒンジ損失関数を使用します。
機械学習の教師あり学習において、損失関数(コスト関数 or 目的関数)というものがあります。
実データと予測データの差を損失といい、これを定義するロジックを損失関数といいます。教師あり学習の多くのアルゴリズムは、この損失を最小にするような予測データを出力できるように、内部の係数を動的に調整していきます。損失はアルゴリズムが予測する為に使う目印と言って良いかもしれません。
#【SGD識別】アルゴリズムの準備 clf_result=linear_model.SGDClassifier(loss="hinge") #ヒンジ損失関数を指定
データセットを学習データセットとテスト(予測実施)データセットに分割します。
今回は90%(135セット)を学習データ、10%(15セット)をテストデータとします。
#データセットを学習とテスト(予測実施)に分割して実行 ds_train, ds_test, ds_train_label, ds_test_label=cross_validation.train_test_split(std_data, label, test_size=0.1, random_state=0) #学習実行 clf_result.fit(ds_train, ds_train_label) #予測実行 pre=clf_result.predict(ds_test)
予測が完了しました。
実際の「class」と予測した「class-predict」を比較してみましょう。
#実際の「class」と予測した「class-predict」を比較 df_result=pd.DataFrame(columns=['class', 'class-predict'], dtype=object) df_result['class']=ds_test_label.reset_index(drop=True) df_result['class-predict']=pre pd.DataFrame(df_result)
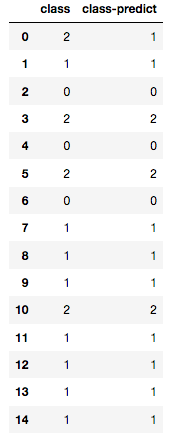
一行目のみ不一致でそれ以外は一致しました。スコアとしては
#スコア出力 ac_score=metrics.accuracy_score(ds_test_label, pre) print(ac_score)
0.933333333333(約93%で予測成功)という結果になりました。
最後に
今回の実践では、アルゴリズム決め打ちで実施しましたが、実際にはK分割交差検証(▷参考)などを用いて精度を確認したり、目的変数(ex アヤメの種類)と説明変数(ex 花びらの長さ・がくの長さ)とでプロットしデータ構造を把握してアルゴリズムを選定していくことになります。
次回は実践に比重を置いたブログにしていきたいと思います。冒頭でも言いましたが、最終的には今回紹介した全てのアルゴリズムを実践することが目標です。最近だと話題のニューラルネットワークアルゴリズムも使えるようになったようですね。引き続き頑張っていきたいと思います…汗。
ご清覧頂きありがとうございました。
Wedding Parkでは一緒に技術のウエディングパークを創っていくエンジニアを募集しています。
興味のある方はぜひ一度気軽にオフィスに遊びにきてください。
◉筆者のおすすめ記事
・やってみよう!AWSでWEBサーバー環境構築(シリーズ第1回)
・やってみよう!AWSでWEBサーバー環境構築(シリーズ第2回)
・やってみよう!AWSでWEBサーバー環境構築(シリーズ第3回)
・やってみよう!AWSでWEBサーバー環境構築(Lambda|API Gateway|シリーズ第4回)
・【DB設計入門|ER図|MySQL】コンビニレシートから学ぶ!データモデリング手法
